In low-level software development, understanding memory layout is very important for optimizing memory usage. One key concept in this domain is structure padding. This post explain deep into structure padding, explaining what it is, why it happens, and how it affects memory usage and performance in C and C++ programs.
Understanding structure padding is particularly important in environments with limited memory, such as embedded systems, where efficient use of memory can significantly impact the performance and feasibility of a project.
Some Examples
Predict the size of the following structures.
typedef struct {
int a;
} datatype0;
typedef struct {
int a;
int b;
} datatype1;
typedef struct {
int a;
char b;
} datatype2;
typedef struct {
int a;
char b;
int c;
} datatype3;
typedef struct {
long b;
int a;
} datatype4;
typedef struct {
long a;
int b;
long c;
} datatype5;
typedef struct {
long long a;
int b;
} datatype6;
The size of the structure depends on the number of bits in the supported architecture. Therefore, the answers are as follows.
Before that we need to understand the size of some primitive data types.
| Data type | 32-Bit arch | 64-Bit arch |
|---|---|---|
| char | 1 | 1 |
| int | 4 | 4 |
| long | 4 | 8 |
| long long | 8 | 8 |
| Datatype Name | Size (32bit arch) | Size (64bit arch) |
|---|---|---|
| datatype0 | 4 | 4 |
| datatype1 | 8 | 8 |
| datatype2 | 8 | 8 |
| datatype3 | 12 | 12 |
| datatype4 | 8 | 16 |
| datatype5 | 12 | 24 |
| datatype6 | 12 | 16 |
If you are not familiar with structure padding, some of your answers might be incorrect. Let’s verify each one step by step. The following C program is used to dump the structure data from RAM. This program will be utilized to analyze structure padding in the rest of this post.
void dump_structure(void *ptr, unsigned long size) {
unsigned long addr;
// Top row of the table
printf("\nSize of the structure: %lu\n ", size);
for(int i = 0; i <= 0xf; i++) {
if(i == 8) printf(" ");
printf(" %x ", i);
}
// Horizontal seprator
printf("\n---------------+--------------------------------------------------");
for(int i = 0; i < size; i++) {
addr = ((unsigned long)(ptr + i));
if((i == 0) && (addr & 0xF)) {
// Set the last digit of address as 0
printf("\n0x%lx | ", addr & ~(0xF));
// If the address is not starting from mod 16
// Add padding with 00 till the data
printf(" 00 00 00 00 00 00 00 00 ");
}
if(addr % 16 == 0) {
// Print address after every 16 bytes
printf("\n0x%lx | ", addr);
}
// A vertical line after 8 bytes
if(addr % 8 == 0) printf(" ");
// Print each bytes
printf("%02x ", *(unsigned char*)(ptr+i));
}
printf("\n\n");
}
Size of datatype0
When I pass datatype0 o this function, I am getting the output something like this.
typedef struct {
int a;
} datatype0;
int main() {
datatype0 data = {0x12345678};
dump_structure(&data, sizeof(data));
}
// Output
Size of the structure: 4
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7beb5f720 | 78 56 34 12
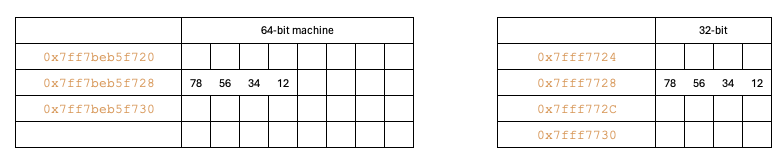
In this scenario, the data contained within the memory addresses ranging from 0x7ff7beb5f728 to 0x7ff7beb5f72b totals 4 bytes, equivalent to the size of an integer. As a result, there is no confusion. Both 32-bit and 64-bit machine give the same output for this example.
Size of datatype1
Now let’s check datatype1.
typedef struct {
int a;
int b;
} datatype1;
int main() {
datatype1 data = {0x12345678, 0x90abcdef};
dump_structure(&data, sizeof(data));
}
// Output
Size of the structure: 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7beb5f720 | 78 56 34 12 ef cd ab 90
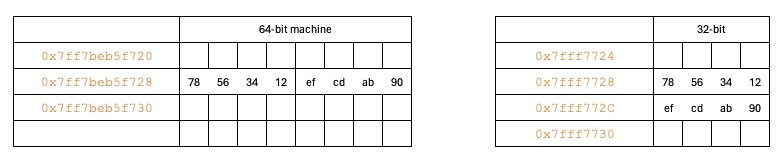
In this scenario, the data within the memory addresses ranging from 0x7ff7beb5f728 to 0x7ff7beb5f72b totals 4 bytes, which is the size of an integer. Therefore, there is no discrepancy; both 32-bit and 64-bit machines produce the same output for this example.
Size of datatype2
for datatype2.
typedef struct {
int a;
char b;
} datatype2;
int main() {
datatype2 data = {0x12345678, 'a'};
dump_structure(&data, sizeof(data));
}
// Output
Size of the structure: 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bdd7f720 | 78 56 34 12 61 00 00 00
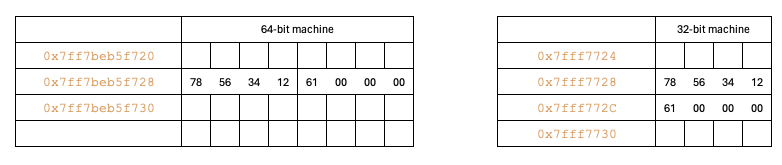
In this scenario, the data stored in the address from 0x7ff7beb5f728 to 0x7ff7beb5f72c. This is expected because the int span over first 4 bytes and char span over the next one byte. So total memory that should be taken is 5 bytes. But as per the code output, the total size is 8 bytes, how?!!!
Principle-1: The size of a structure will always be a multiple of the size of the largest data type in that structure or the size of the bit architecture (whichever is smaller).
Here the largest data type is in (4 bytes) on both 32-bit and 64-bit machines. So the remaining spaces will be filled with 0s as you see above. This extra spaces called structure padding. If another data of type char is added as third member (eg ‘b’) in the datatype2 structure, the location for this data will be taken from this structure padding.
// Output
Size of the structure: 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bdd7f720 | 78 56 34 12 61 62 00 00
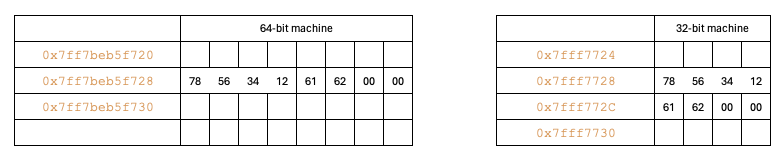
If we add 3 more char data (total 1 int and 5 char) total 8 bytes will be taken when we add 1st and 2nd char by taking the space from padding. When we add the third char, there is no more spaces, so it will add next chunk of data with size of largest data type (int – 4 bytes) to the existing memory size. So total becomes 12-bytes.
// Output
Size of the structure: 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bdd7f720 | 78 56 34 12 61 62 63 64
0x7ff7bdd7f730 | 65 00 00 00
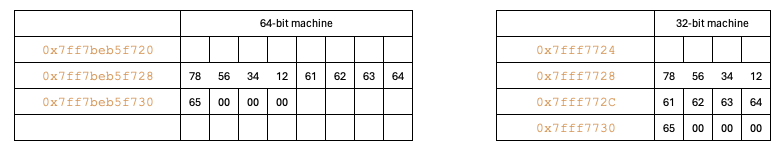
Size of datatype3
typedef struct {
int a;
char b;
int c;
} datatype3;
int main() {
datatype3 data = {0x12345678, 'a', 0x12345678};
dump_structure(&data, sizeof(data));
}
// Output
Size of the structure: 12
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bdd7f720 | 78 56 34 12 61 00 00 00 78 56 34 12
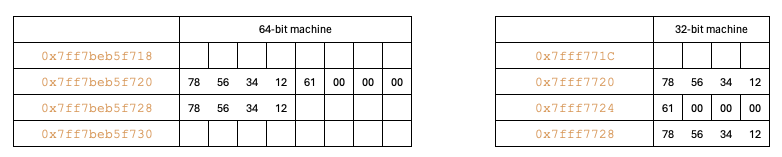
In this scenario, data is stored at addresses from 0x7ff7beb5f720 to 0x7ff7beb5f72b. The structure includes three 0s after the character. Although the last integer could start immediately after the char 'a' (61), padding is added to ensure that the starting address is a multiple of its size.
Principle-2: Each member of a structure will be stored in memory such that the starting address of the member is a multiple of its size.
Size of datatype4
One of the members in datatype4 is a long. The size of long is architecture-dependent, so we need to check both cases separately.
typedef struct {
long a;
int b;
} datatype4;
int main() {
#if defined(__LP64__) || defined(_LP64)
// 64-bit arch
datatype4 data = {0x1234567812345678, 0x11223344};
#else
// 32-bit arch
datatype4 data = {0x12345678, 0x11223344};
#endif
dump_structure(&data, sizeof(data));
}
// Output 32-bit machine
Size of the structure: 8
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7b270f720 | 78 56 34 12 44 33 22 11
// Output 64-bit machine
Size of the structure: 16
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7b8cf9720 | 78 56 34 12 78 56 34 12 44 33 22 11 00 00 00 00
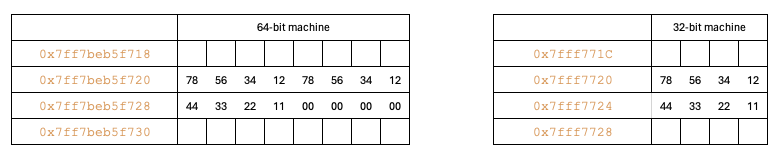
In a 32-bit architecture, long is 4 bytes in size, so it will work exactly the same as the int data type.
We can apply Principle 1 to a 64-bit architecture. Since there is only one integer after the long, padding will be added to the remaining space to ensure the total size is a multiple of the size of the long.
Size of datatype5
In datatype5 there are two long data and one int in between them.
typedef struct {
long a;
int b;
long c;
} datatype4;
int main() {
#if defined(__LP64__) || defined(_LP64)
datatype4 data = { 0x1234567812345678, 0x11223344, 0x1234567812345678 };
#else
datatype4 data = { 0x12345678, 0x11223344, 0x12345678 };
#endif
dump_structure(&data, sizeof(data));
}
// Output 32-bit machine
Size of the structure: 12
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7b270f720 | 78 56 34 12 44 33 22 11 78 56 34 12
// Output 64-bit machine
Size of the structure: 24
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bfea8710 | 78 56 34 12 78 56 34 12
0x7ff7bfea8720 | 44 33 22 11 00 00 00 00 78 56 34 12 78 56 34 12
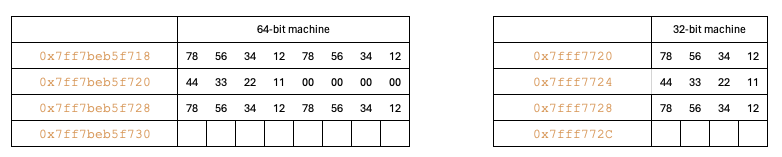
In a 64-bit machine output, the second long member could start immediately after the int. However, padding is added between them due to the third principle.
Principle-3: The data will be aligned to minimize the number of CPU cycles required for reading. A 32-bit CPU reads 32 bits per cycle, while a 64-bit CPU reads 64 bits per cycle.
In a 32-bit architecture, the starting address of memory on each cycle will be the multiples of 8. In contrast, in a 64-bit architecture, starting address will be multiples of 16.
Size of datatype6
In datatype6 there is a long long data and an int. Since the size of long long is same on both the 32-bit and 64-bit machine, we don’t need to use the macro in the code.
typedef struct {
long long a;
int b;
} datatype5;
int main() {
datatype4 data = { 0x1111222233334444, 0x11223344 };
dump_structure(&data, sizeof(data));
}
// Output 32-bit machine
Size of the structure: 12
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bfea8720 | 44 44 33 33 22 22 11 11 44 33 22 11
// Output 64-bit machine
Size of the structure: 16
0 1 2 3 4 5 6 7 8 9 a b c d e f
---------------+--------------------------------------------------
0x7ff7bfea8720 | 44 44 33 33 22 22 11 11 44 33 22 11 00 00 00 00
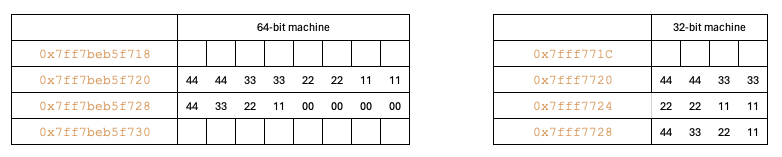
In a 64-bit machine, both the data and address buses are 64 bits wide, meaning data is aligned to 64-bit (8-byte) boundaries. Consequently, the maximum data size that can be read in a single cycle is 64 bits (8 bytes).
In contrast, a 32-bit machine has 32-bit wide data and address buses, so data is aligned to 32-bit (4-byte) boundaries. The maximum data size that can be read in a single cycle is 32 bits (4 bytes). Therefore, reading a long long data type (which is 64 bits or 8 bytes) would require two CPU cycles.
As a result, in a 32-bit machine, the next int (which is 32 bits) after the long long does not add extra space because it will fully occupy the 32-bit width.
Conclusion
In summary, these principles outline fundamental aspects of memory management and data alignment in programming, particularly in low-level languages like C and C++. By ensuring that structures are sized and aligned according to these principles, programmers can optimize memory usage, enhance data access efficiency, and ensure compatibility across different CPU architectures. Principle-1 ensures that structure sizes are managed efficiently, Principle-2 guarantees that individual data members are stored in memory in a predictable manner, and Principle-3 underscores the importance of aligning data to match the CPU’s processing capabilities, thereby minimizing overhead and improving performance. Understanding and applying these principles are crucial for developing robust and efficient software that leverages the capabilities of modern computing systems.